Using RunPy
In this guide, we will learn to import Python libraries in your applications.
If you are new to using RunPy queries, check out our guide on how to get started with RunPy. ToolJet supports installing libraries using micropip. Check out this documentation for a list of supported libraries.
Installing Python Packages
In ToolJet, you can write Python code for custom logic, and for intensive data processing tasks, you can use Python libraries without needing to write complex code from scratch. Here’s how you can use them:
You can use micropip to install packages like Pandas and NumPy as follows:
import micropip
await micropip.install('pandas')
await micropip.install('numpy')
Trigger this RunPy query once to install these packages.
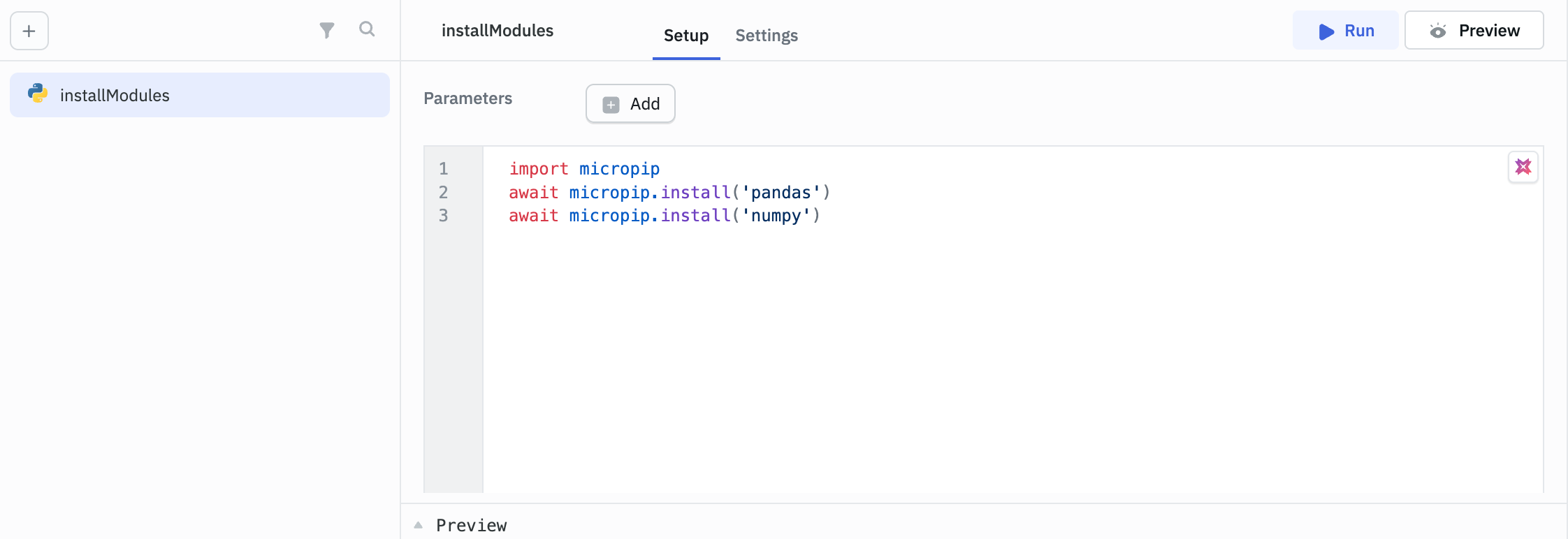
Enable the Run this query on application load option in the query settings to make the libraries available throughout the application as soon as the app is loaded.
Use Cases
Parse CSV Data
Let’s say you want users to upload a CSV and view the parsed output. Here’s how you can use pandas and Python’s CSV module. Create a RunPy query to parse CSV data using StringIO, csv, and Pandas module.
from io import StringIO
import csv
import pandas as pd
scsv = components.filepicker1.file[0].content
f = StringIO(scsv)
reader = csv.reader(f, delimiter=',')
df = pd.DataFrame(reader)
print(df.info())
print(df)
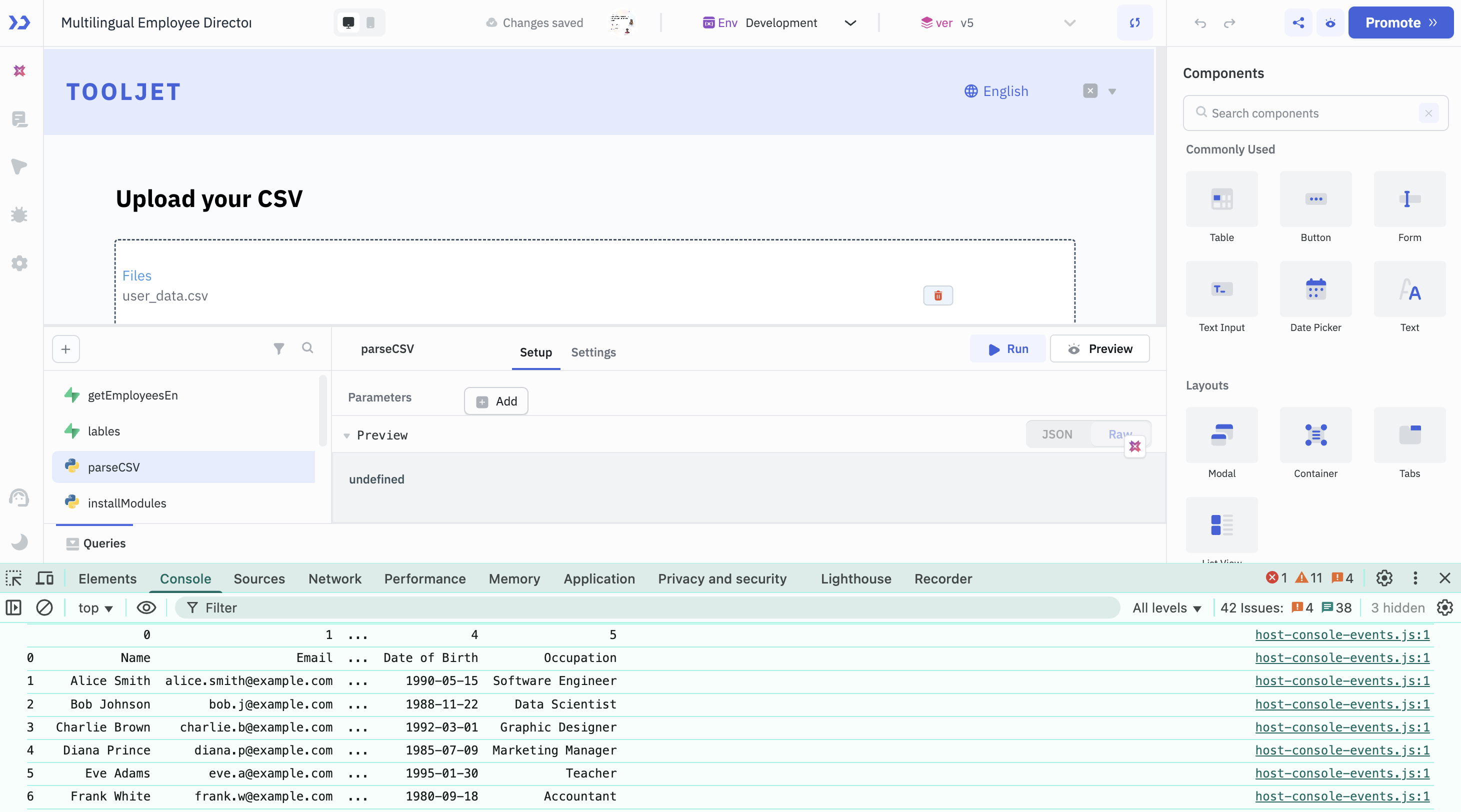
- Add a File Picker to your app and change the file type to CSV.
- In the File Picker’s event settings:
- Event: On File Loaded
- Action: Run Query → choose your RunPy script
- Upload a CSV file. When you trigger the RunPy query, it will parse the data and output it in the browser console
Prompt Preprocessing for AI APIs
When building apps that integrate with AI APIs (like OpenAI, Cohere, or HuggingFace), you often need to send long-form text inputs—like meeting transcripts, user feedback, or document excerpts to the API. However, many AI APIs have input size limitations (e.g., 4,096 tokens for GPT-3.5), and they often work best when the input is clean and concise.
So, before sending the data, you may want to:
- Clean and normalize the text (remove line breaks, extra spaces, non-ASCII characters)
- Chunk the text into API-safe sizes (e.g., 500 characters or 300 words)
- Optionally, remove irrelevant sections (like headers, boilerplate, or disclaimers)
Here's an example of how to do this preprocessing step using regular expressions (re):
import re
# Get raw text from a multi-line input component (like a long form or a textarea)
raw_text = components.textarea1.text
# 1. Clean the text
cleaned = re.sub(r"\s+", " ", raw_text).strip()
# 2. Chunk the cleaned text into slices of 500 characters each
chunks = [cleaned[i:i+500] for i in range(0, len(cleaned), 500)]
# Output the cleaned and chunked data
print({"chunks": chunks})
Input - Meeting notes
We discussed the Q3 roadmap and agreed to prioritize performance improvements. There were also suggestions to improve the onboarding experience.
Action items:
- Alice will investigate caching issues and report back by next Monday.
- Bob will look into UI responsiveness across different screen sizes.
- Carol will start planning for the user feedback survey in Q4.
Additional Discussion:
- A proposal was made to reduce build times by moving to a newer CI/CD system.
- Concerns were raised about backend API reliability and latency issues.
- Data team mentioned they are behind on setting up the new dashboard pipeline.
Next Steps:
- Weekly check-ins will resume starting next Tuesday.
- Each team will submit a biweekly progress report.
- Planning for the product demo scheduled for November 15th will start next week.
Output - Chunked data
{
"chunks": [
"We discussed the Q3 roadmap and agreed to prioritize performance improvements. There were also suggestions to improve the onboarding experience. Action items: - Alice will investigate caching issues and report back by next Monday. - Bob will look into UI responsiveness across different screen sizes. - Carol will start planning for the user feedback survey in Q4.",
"Additional Discussion: - A proposal was made to reduce build times by moving to a newer CI/CD system. - Concerns were raised about backend API reliability and latency issues. - Data team mentioned they are behind on setting up the new dashboard pipeline. Next Steps: - Weekly check-ins will resume starting next Tuesday. - Each team will submit a biweekly progress report. - Planning for the product demo scheduled for November 15th will start next week."
]
}